Paper Discussion: SODA-OPT
Slides
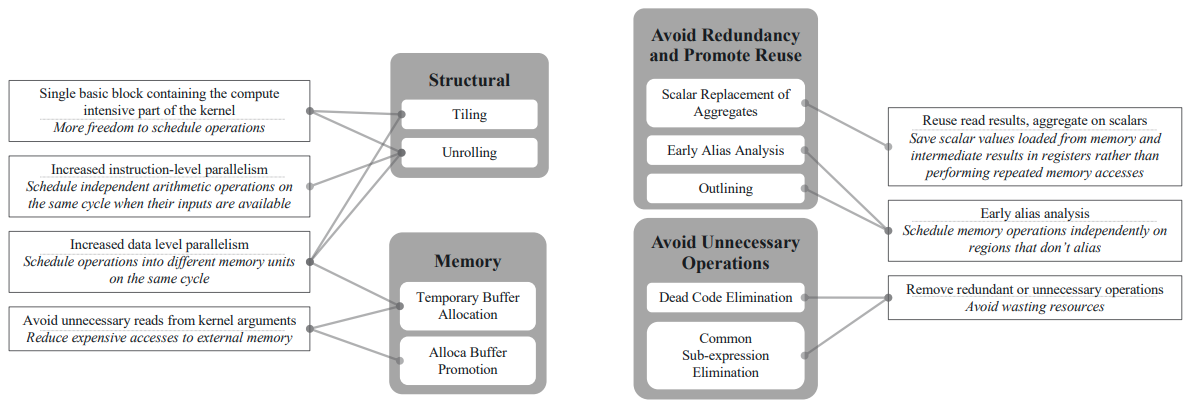
Motivation
- Mapping applications into Custom Hardware.
- Extract Performance.
- Heavy manual intervention.
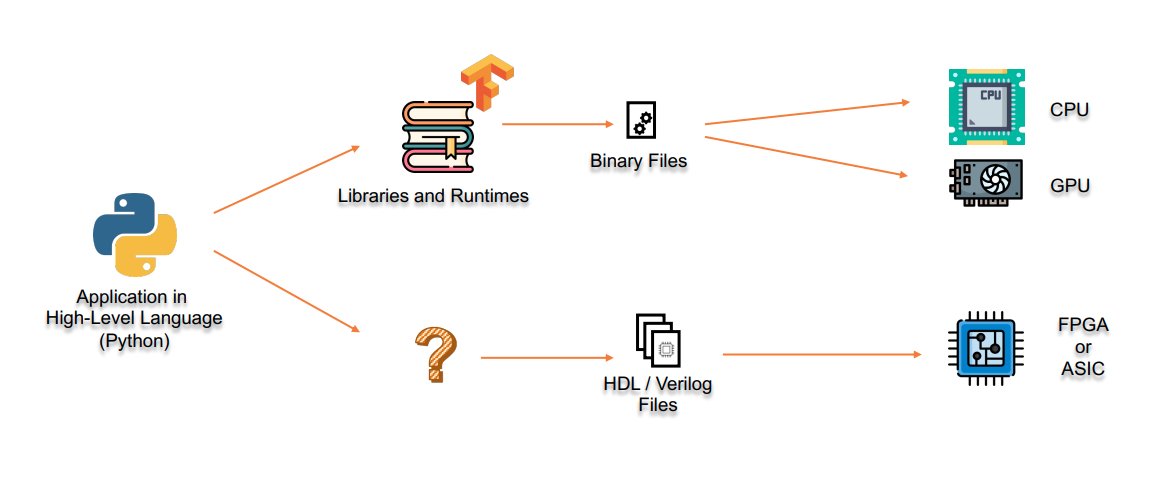
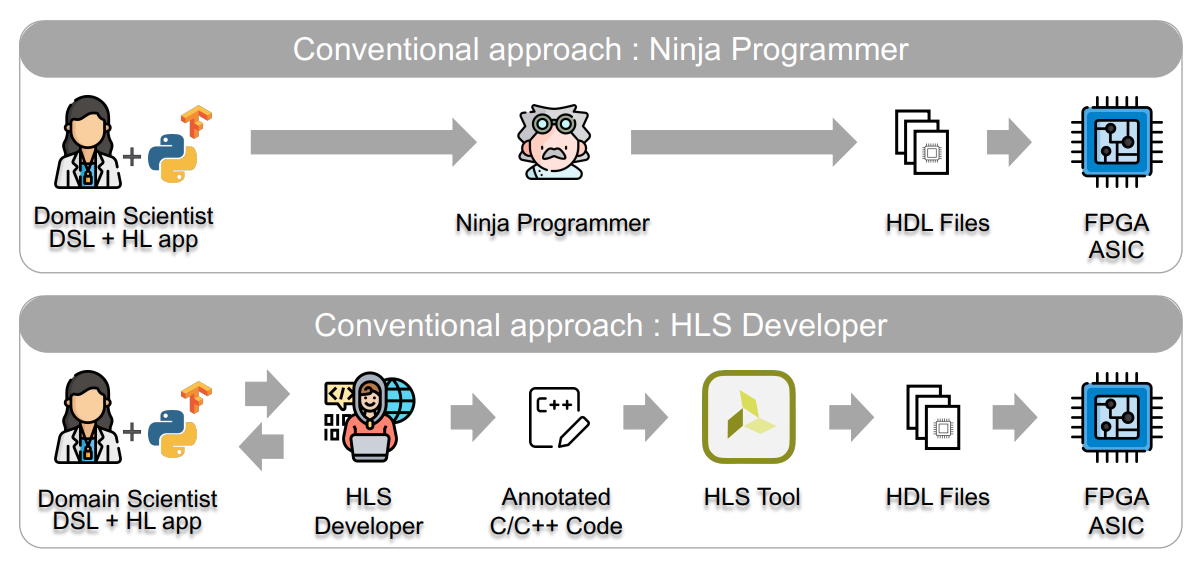
SODA-OPT
- MLIR-based inputs
- Supports any high-level application that can be converted into
linalg,affinedialects
- Supports any high-level application that can be converted into
- System-Level Design
- high-level optimizations for the HLS backends
- DSE of compiler options
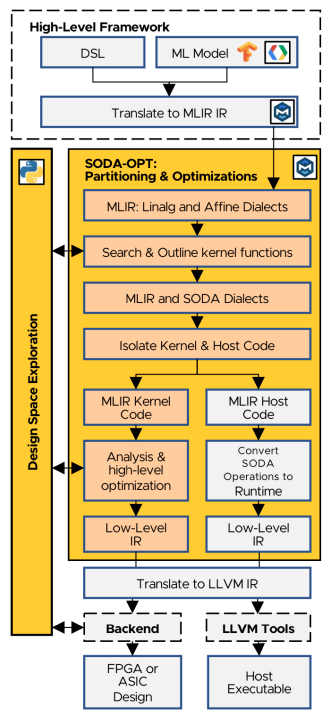
Workflow (in paper)
- ML model in python (Tensorflow)
- Convert model to MLIR (tf dialect) & Lower to
TOSA - Lower to
linalgMLIR dialect - This work
- Select MLIR code for custom accelerator generation
- Optimize kernel code and generate IR for HLS (Bambu)
- Synthesize baseline and optimized code into Verilog
- Place and route synthesized code, generate final GDSII

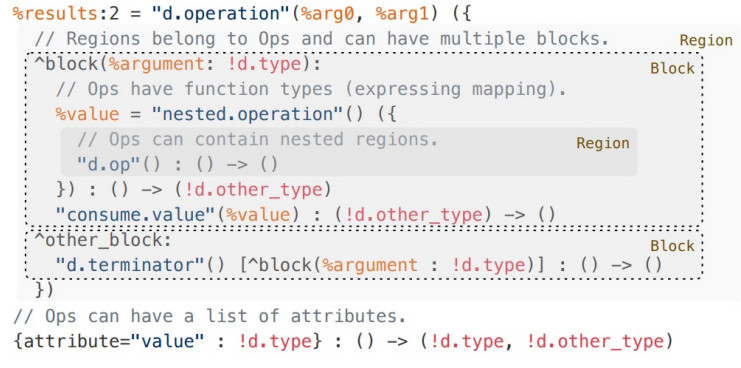
Background
Multi-Level Intermediate Representation Compiler Infrastructure
- Open-source
- Progressive lowering between existing and new operations
- Reuse of abstractions and compiler transformations
- Enables co-existence of different abstractions
MLIR - Example
// Linalg abstraction
func.func dot(%A: memref<100xf32>, %B: memref<100xf32>, %out: memref<f32>){
linalg.dot ins(A, B: memref<100xf32>, memref<100xf32>) outs(%out: memref<f32>)
return
}// SCF abstraction
func.func @dot(%A: memref<100xf32>, %B: memref<100xf32>, %out: memref<f32>){
%c0 = arith.constant 0 : index
%c100 = arith.constant 100 : index
%cl = arith.constant 1 : index
scf.for %arg3 = %c0 to %c100 step %c1 {
%0 = memref.load %A[%arg3] : memref<100xf32>
%1 = memref.load %B[%arg3] : memref<100xf32>
%2 = memref.load %out[] : memref<f32>
%3 = arith.mulf %0, %1 : f32
%4 = arith.addf %2, %3 : f32
memref.store %4 , %out[] : memref<f32>
}
return
}// CF abstraction
func.func @dot(%A: memref<100xf32>, %B: memref<100xf32>, %out: memref<f32>){
%c0 = arith.constant 0 : index
%c100 = arith.constant 100 : index
%c1 = arith.constant 1 : index
cf.br ^bb1(&c0 : index)
^bb1(%0: index): // 2 preds: ^bb0, ^bb2
%1 = arith.cmpi slt, %0, %c100 : index
cf.cond_br %1, ^bb2, ^bb3
^bb2: // pred: ^bb1
%2 = memref.load %A[%arg3] : memref<100xf32>
%3 = memref.load %B[%arg3] : memref<100xf32>
%4 = memref.load %out[] : memref<f32>
%5 = arith.mulf %2, %3 : f32
%6 = arith.addf %4, %5 : f32
memref.store %6 , %out[] : memref<f32>
%7 = arith.addi %0, %c1 : index
cf.br ^bb1(%7 : index)
^bb3: // pred: ^bb1
return
}Optimization