Homework 3: Data Flow
Introduction
This assignment focuses on implementing dataflow analysis for the Bril intermediate language to support three major analyses: liveness, availability, and busy expressions. These analyses play a crucial role in various compiler optimizations, including Trivial Dead Code Elimination (DCE) and Local Value Numbering (LVN) that we discussed and implemented in previous homework, HW2. The goal is to analyze the flow of data within a program, identify redundant or unnecessary computations, and determine which values are still “live” or “in use” at various points in a program.
The report details the design of a flexible framework for these analyses, the implementation strategy for each type of dataflow analysis, and the use of visualization to display the results. The integration and testing process ensures the framework’s correctness through various benchmark tests, and the results are analyzed to demonstrate its effectiveness.
Interactive Demo
Detail Design
Check EECE7398_ST_Compiler/HW3 for source code.
Abstraction Classes
The abstraction class remain the same structure as last homework submittion, see detail in HW2 - Abstraction Classes.
I add some additional features and fix something like __repr__ for some of the classes, therefore use current ./bril_model for further development.
Graph Result Demonstration
Since this task is about analizing some properties of the data-flow graph, a better way to demonstrate it clear and straight forward is to show the computated result in visual format. I developed the framework to view analyze results using vis.js and networkx.
🚧 Expand HERE for HD Video

Dataflow Analysis Implementation
The script df_analysis.py performs dataflow analysis on Bril programs, supporting three types of analysis: liveness, availability, and busy expressions. The implementation is designed to be generic, allowing for easy extension to other types of dataflow analysis with minimal code changes.
1. Argument Parsing and Setup
The script begins by utilizing the argparse module to handle command-line argument parsing. This allows the user to specify three key arguments when running the script:
ANALYSIS: Specifies the type of dataflow analysis to perform. The valid options are'liveness','availability', or'busy'. This argument is required and ensures the script knows what kind of analysis to perform on the Bril program.DEMO_BRIL_FILE: This is the path to the Bril program that will be analyzed. The file contains the intermediate representation (IR) of the program.--save-dir: An optional argument that specifies where to save the generated output HTML files (visualizations). If not provided, the default directory./saveis used.
By parsing these arguments, the script can dynamically handle different types of analysis and ensure the correct files are processed and results saved to the right locations.
EECE7398_ST_Compiler(601e0e9) :: HW3/df_analysis.py :: Lines 20 to 25
import argparse
parser = argparse.ArgumentParser(description='Generate data flow graph for a bril script')
parser.add_argument('ANALYSIS', type=str, help='Analysis: [liveness, availability, busy]')
parser.add_argument('DEMO_BRIL_FILE', type=str, help='Path to the bril file')
parser.add_argument('--save-dir', type=str, default='./save', help='Path to save the generated html files')
args = parser.parse_args() 2. Validation of Arguments
Once the arguments are parsed, the script proceeds to validate them:
ANALYSIS: The provided value is converted to lowercase for consistency. The script checks whether the specified analysis type is one of the allowed options:'liveness','availability', or'busy'. If the user specifies an unsupported analysis, the script prints an error message and exits.DEMO_BRIL_FILE: The script checks if the provided file path exists on the system. If not, an error message is displayed, and the script terminates.- If all validations pass, the script proceeds with the execution; otherwise, it prints the usage information (
parser.print_help()) to guide the user on how to run the script correctly.
This ensures that only valid input and analysis types are processed.
EECE7398_ST_Compiler(601e0e9) :: HW3/df_analysis.py :: Lines 27 to 43
ANALYSIS = args.ANALYSIS.lower()
DEMO_BRIL_FILE = args.DEMO_BRIL_FILE
# how to get the save-dir value
SAVE_DIR = args.save_dir
# make sure args are allowed
correct = True
if ANALYSIS not in ['liveness', 'availability', 'busy']:
print(f"Analysis <{ANALYSIS}> not supported")
correct = False
if not os.path.exists(DEMO_BRIL_FILE):
print(f"File <{DEMO_BRIL_FILE}> not found")
correct = False
if not correct:
# print help and exit
parser.print_help()
exit(1) 3. Loading the Bril Script
The script loads the Bril program into a BrilScript object, which represents the structure of the input program. This object provides an abstraction over the Bril instructions and functions, making it easier to manipulate and analyze.
- The
BrilScriptobject is initialized with the name of the file, and the control flow graph (CFG) for each function in the Bril script is constructed. The CFG represents how control flows between basic blocks (sequences of instructions without branches) in each function, which is crucial for performing dataflow analysis. app_graphis a dictionary that maps eachBrilFunctionto a tuple consisting of anetworkxdirected graph (the CFG) and a mapping of labels to their corresponding instructions.
The CFG provides the foundation for performing various types of dataflow analysis, as it organizes the program’s structure into a form that can be traversed and analyzed.
EECE7398_ST_Compiler(601e0e9) :: HW3/df_analysis.py :: Lines 135 to 137
bbs = bm.BrilScript(script_name=os.path.basename(DEMO_BRIL_FILE), file_dir=os.path.dirname(DEMO_BRIL_FILE))
app_graph: Dict[bm.BrilFunction, Tuple[nx.DiGraph, Dict[bm.BrilInstruction_Label, List[bm.BrilInstruction]]]] = {}
update_to_graph(bbs, app_graph) 4. Generating GEN, KILL, and EXPR Sets
For each basic block, the script calculates three sets:
GEN: The set of variables used before being assigned a new value in the block. These are the variables that “generate” dependencies in the block.KILL: The set of variables that are redefined or “killed” within the block.EXPR: The set of expressions that are still available at the end of the block.
The function get__args_used_before_assign__assigned__calc_expr_available_at_bb_end iterates over the instructions in a basic block. It collects the following information: - used_first: Variables that are used before any assignment in the block. - written: Variables that are assigned new values within the block. - avail_exprs: Expressions that remain available for future use at the end of the block, ensuring that they haven’t been invalidated by any assignments.
The GEN, KILL, and EXPR sets are essential for performing dataflow analysis like liveness and availability, which rely on tracking how variables and expressions evolve over the program.
EECE7398_ST_Compiler(601e0e9) :: HW3/df_analysis.py :: Lines 150 to 168
def get__args_used_before_assign__assigned__calc_expr_available_at_bb_end(instrs: List[bm.BrilInstruction]) -> Tuple[Set[str],Set[str],Set[Expr]]:
"""
Given a list of instructions, return the set of variables that are used before defined and the set of variables that are modified.
This is from HW2, but modified to return the sets instead of printing them.
"""
used_first: Set[str] = set()
written: Set[str] = set()
avail_exprs: Set[Expr] = set()
for instr in instrs:
used_first.update(set(instr.args if instr.args else []) - written)
if instr.dest:
# check if the dest was used in generating any of the expressions, if so, remove it from exprs
for expr in list(avail_exprs):
if instr.dest in expr.args:
avail_exprs.remove(expr)
written.add(instr.dest)
if instr.args and instr.op not in ['id', 'const', 'call']:
avail_exprs.add(Expr(instr.op, instr.args))
return used_first, written, avail_exprs 5. Updating GEN, KILL, and EXPR Sets
After calculating the GEN, KILL, and EXPR sets for each basic block, the script updates the CFG with this information. The update_gen_kill_sets function iterates over each node (basic block) in the CFG and stores the calculated GEN, KILL, and EXPR sets in the node’s attributes.
This step enriches the CFG with the necessary dataflow information, setting up the foundation for more complex analyses like determining which variables are live or which expressions are available.
EECE7398_ST_Compiler(601e0e9) :: HW3/df_analysis.py :: Lines 173 to 180
def update_gen_kill_sets(app_graph: Dict[bm.BrilFunction, Tuple[nx.DiGraph, Dict[bm.BrilInstruction_Label, List[bm.BrilInstruction]]]]):
for _, (fdg, _) in app_graph.items():
for each_node, each_node_data in fdg.nodes(data=True):
each_block: List[bm.BrilInstruction] = each_node_data.get('instructions', None)
_gen, _kill, _expr = gen_kill_expr_sets(each_block) if each_block else (set(), set(), set())
fdg.nodes[each_node]['GEN'] = _gen
fdg.nodes[each_node]['KILL'] = _kill
fdg.nodes[each_node]['EXPR'] = _expr 6. Generic Dataflow Analysis
The script defines a generic dataflow analysis function _fdg_update_bare_bone, which can be adapted for different types of analyses (liveness, availability, busy expressions). This function operates by traversing the CFG and updating the IN and OUT sets of each node (basic block):
IN: The set of variables or expressions that are live or available at the entry to a basic block.OUT: The set of variables or expressions that are live or available at the exit of a basic block.
The function takes as input a specific analysis function (e.g., for liveness or availability) and applies it to update the IN and OUT sets for each node. The function also checks whether the IN and OUT sets change during the analysis—if they do, it indicates that the dataflow information has propagated, and further iterations are required.
The generic nature of this function minimizes code duplication and allows the script to easily switch between different types of analyses.
EECE7398_ST_Compiler(601e0e9) :: HW3/df_analysis.py :: Lines 202 to 213
def _fdg_update_bare_bone(specific_analysis_func: Callable[[nx.DiGraph, str], Tuple[Set[str], Set[str]]], fdg: nx.DiGraph) -> bool:
# here we extract the common part of the analysis
has_changed = False
for this_node, _ in fdg.nodes(data=True):
_print_this_node_name = this_node.replace('\n', '\\n')
_in, _out = specific_analysis_func(fdg, this_node)
print(f"Node: {_print_this_node_name}, IN: {_in}, OUT: {_out}")
if _in != _get_node_in_set(fdg, this_node) or _out != _get_node_out_set(fdg, this_node):
fdg.nodes[this_node]['IN'] = _in
fdg.nodes[this_node]['OUT'] = _out
has_changed = True
return has_changed 7. Specific Analysis Functions
The script defines specific analysis functions for each type of dataflow analysis:
Liveness Analysis: Computes the
INandOUTsets based on the liveness of variables. It updates the sets by looking at the successors of each node and determining which variables are still live at the entry of a basic block.Availability Analysis: Determines which expressions are available at the entry and exit of a block. It considers the predecessor nodes and checks whether the expressions remain valid by avoiding any variables that were killed in the block.
Busy Expressions Analysis: Identifies which expressions must be computed before reaching the next use of a variable. This analysis is useful for identifying common subexpressions that can be optimized.
Each function is passed to the generic _fdg_update_bare_bone function to perform the corresponding analysis.
EECE7398_ST_Compiler(601e0e9) :: HW3/df_analysis.py :: Lines 215 to 258
def _fdg_update_internal_liveness_sets(fdg: nx.DiGraph, this_node: str) -> Tuple[Set[str], Set[str]]:
"""
this.gen = {v | v is used before defined here}
this.kill = {v | v is assigned here}
IN = this.gen + (OUT - this.kill)
OUT = union(successors' IN)
"""
_print_this_node_name = this_node.replace('\n', '\\n')
_temp_succ_req = [_get_node_in_set(fdg, each_succ_node) for each_succ_node in _get_node_succ_set(fdg, this_node)]
_out: Set[str] = set.union(*_temp_succ_req) if _temp_succ_req else set()
print(f"Node: {_print_this_node_name}, Succ: {_get_node_succ_set(fdg, this_node)}=>{_temp_succ_req}, OUT: {_out}")
_in: Set[str] = set.union(_get_node_gen_set(fdg, this_node), set.difference(_out, _get_node_kill_set(fdg, this_node)))
return _in, _out
def _fdg_update_internal_availability_sets(fdg: nx.DiGraph, this_node: str) -> Tuple[Set[Expr], Set[Expr]]:
"""
this.exprs = {e | e is available at the end of the block}
IN = intersection(predeccessors' OUT)
OUT = (IN + this.exprs) - OUT(expr: any(var modified here exist in expr))
"""
_print_this_node_name = this_node.replace('\n', '\\n')
_temp_pred_give = [_get_node_out_set(fdg, each_pred_node) for each_pred_node in _get_node_pred_set(fdg, this_node)]
_in: Set[Expr] = set.intersection(*_temp_pred_give) if _temp_pred_give else set()
print(f"Node: {_print_this_node_name}, Pred: {_get_node_pred_set(fdg, this_node)}=>{_temp_pred_give}, IN: {_in}")
# gatter all exprs that were computed before the end of this block
_out: Set[Expr] = set.union(_get_node_in_set(fdg, this_node), _get_node_expr_set(fdg, this_node))
# remove such expr that include variables that were modified in this block
_out = set([each_expr for each_expr in _out if not set.intersection(set(each_expr.args), _get_node_kill_set(fdg, this_node))])
return _in, _out
def _fdg_update_internal_busy_sets(fdg: nx.DiGraph, this_node: str) -> Tuple[Set[Expr], Set[Expr]]:
"""
IN = (OUT - OUT(expr: any(var modified here exist in expr)) + this.exprs
OUT = intersection(successors' IN)
"""
_print_this_node_name = this_node.replace('\n', '\\n')
_temp_succ_req = [_get_node_in_set(fdg, each_succ_node) for each_succ_node in _get_node_succ_set(fdg, this_node)]
_out: Set[Expr] = set.intersection(*_temp_succ_req) if _temp_succ_req else set()
print(f"Node: {_print_this_node_name}, Succ: {_get_node_succ_set(fdg, this_node)}=>{_temp_succ_req}, OUT: {_out}")
# remove such expr that include variables that were modified in this block
_in: Set[Expr] = set([each_expr for each_expr in _out if not set.intersection(set(each_expr.args), _get_node_kill_set(fdg, this_node))])
# add all exprs that are computed in this block
_in = set.union(_in, _get_node_expr_set(fdg, this_node))
return _in, _out 8. Running the Analysis
The update_analysis_sets function orchestrates the execution of the selected analysis. Based on the user’s input (liveness, availability, or busy), the corresponding analysis function is retrieved from a mapping (ANALYSIS_FUNC).
The analysis is executed iteratively, updating the CFG with the calculated IN and OUT sets until no further changes occur. This iterative approach is necessary because dataflow analysis typically involves propagating information through the CFG until a fixed point is reached (i.e., the point where further iterations don’t change the dataflow sets).
EECE7398_ST_Compiler(601e0e9) :: HW3/df_analysis.py :: Lines 266 to 277
def update_analysis_sets(analysis_type_str: str , app_graph: Dict[bm.BrilFunction, Tuple[nx.DiGraph, Dict[bm.BrilInstruction_Label, List[bm.BrilInstruction]]]]):
analysis_func = ANALYSIS_FUNC.get(analysis_type_str, None)
if not analysis_func:
print(f"Analysis <{analysis_type_str}> not supported")
return
has_changed = True
while has_changed:
has_changed = False
print(f"Updating {analysis_type_str} sets")
for _, (fdg, _) in app_graph.items():
has_changed |= _fdg_update_bare_bone(analysis_func, fdg)
print() 9. Visualization
The script concludes by generating a visual representation of the CFG using the pyvis library. It creates an interactive HTML file that displays the CFG along with the computed IN, OUT, GEN, KILL, and EXPR sets for each basic block.
- The
dump_into_pv_graphfunction takes the CFG as input and converts it into a visual format. For each node (basic block) in the CFG, theIN,OUT,GEN,KILL, andEXPRsets are formatted as strings and added as attributes to the node in the visualization. - The visualization allows users to interact with the CFG, inspect the dataflow information for each node, and understand the results of the analysis in a more intuitive manner.
This final step provides a clear and accessible way to verify the results of the analysis.
EECE7398_ST_Compiler(601e0e9) :: HW3/df_analysis.py :: Lines 318 to 376
for node in net.nodes:
node['IN'] = _in = generate_set_str(node.pop('IN', set()))
node['OUT'] = _out = generate_set_str(node.pop('OUT', set()))
node['GEN'] = _gen = generate_set_str(node.pop('GEN', set()))
node['KILL'] = _kill = generate_set_str(node.pop('KILL', set()))
node['EXPR'] = _expr = generate_set_str([str(x) for x in node.pop('EXPR', set())])
node['title'] = ''
if 'instructions' in node:
# remove 'data' key from node, and set 'title' key to the string representation of the data
node['title'] = "\n ".join([obj.to_briltxt() if hasattr(obj, 'to_briltxt') else str(obj) for obj in node.pop('instructions', [])])
node['shape'] = 'box'
node['title'] += "\n"
node['title'] += f"\nGEN: { _gen }"
node['title'] += f"\nKILL: { _kill }"
node['title'] += f"\nEXPR: { _expr }"
node['title'] += f"\nIN: { _in }"
node['title'] += f"\nOUT: { _out }"
# title layout change (word replace):
# strip: remove leading/trailing spaces, tabs, newlines, and carriage returns
# double return -> dash line
# double space -> full corner single space
node['title'] = node['title'].strip(' \t\n\r').replace('\n\n', '\n--------\n').replace(' ', '\u3000')
# node['label'] = f"IN: {_in}" + '\n' + node['label'] + '\n' + f"OUT: {_out}"
if node['id'] in (ENTRY_POINT_NAME, RETURN_POINT_NAME):
node['color'] = 'grey'
node['shape'] = 'circle'
for edge in net.edges:
_reason = edge.pop('reason', None)
if _reason:
edge['label'] = _reason
_src_node, _dst_node = _get_node_by_name(edge['from']), _get_node_by_name(edge['to'])
if _src_node and _dst_node and 'OUT' in _src_node and 'IN' in _dst_node:
src_id, src_out, dst_id, dst_in = _src_node['id'], _src_node['OUT'], _dst_node['id'], _dst_node['IN']
if src_out == CONST_EMPTY_STR: src_out = dst_in
if dst_in == CONST_EMPTY_STR: dst_in = src_out
new_label = f"{src_id}.OUT:{src_out}\n{dst_id}.IN:{dst_in}" if src_out != dst_in else src_out
edge['title'] = edge.get('title', "") + edge.get('label', "") # move label to popup title
edge['label'] = new_label # set new label
return net
# Safe linux fs name
safe_fs_name = lambda raw_string: "".join(c if c.isalnum() or c in (' ', '.', '_') else '_' for c in raw_string)
for each_func in bbs.functions:
# Remove illegal characters for Linux filesystem
save_dir = os.path.join(SAVE_DIR, safe_fs_name(bbs.script_name), ANALYSIS)
save_file = f"{safe_fs_name(each_func.name)}.html"
# get the function directed graph
fdg, _ = app_graph.get(each_func)
# mkdir -p ./save_dir
os.makedirs(f"./{save_dir}", exist_ok=True)
# save to html
dump_into_pv_graph(fdg).save_graph(os.path.join(save_dir, save_file)) Conclusion
The script of df_analysis.py provides a flexible and extensible framework for performing dataflow analysis on Bril programs. By defining generic functions and specific analysis functions, it minimizes code duplication and allows for easy addition of new analysis types. The visualization step helps in understanding the results of the analysis by generating an interactive HTML representation of the CFG.
Integration and Testing
The integration of the optimizations was done manually and thoroughly tested to ensure correctness. Testing was carried out using both class examples and official test cases from the Bril repository.
Manual Testing: To validate the correctness of the dataflow analysis, I manually executed the script on several examples provided during class lectures. This helped confirm that the basic dataflow functionality (liveness, availability, and busy expression analysis) was functioning as expected. To test each step of the workflow, use the playground.ipynb to break between steps and check output of each cell.
Class Examples: I tested the implementation with in-class examples, which serve as benchmarks for the expected output of liveness and availability analysis. Each example was carefully compared with the correct CFG and dataflow analysis results.
Bril Benchmark Tests: Additionally, I tested the system on Bril’s official dataflow test cases found in bril/examples/test/df/*.bril. These benchmark examples cover edge cases and typical control flow scenarios, further ensuring the robustness of the implementation.
Other Benchmarks: Beyond the standard tests, I applied the analysis to select benchmarks from bril/benchmarks/core. These more complex scenarios helped confirm that the system could scale effectively while maintaining correct results.
Across all test cases, the output CFGs and the results of liveness, availability, and busy expressions analysis were consistent with the expected behavior. No discrepancies were found during manual inspection or benchmark comparisons.
BTW, to rerun all results that I submitted to this repo, just simply use make.
Results and Analysis
To make life easier, the Bril scripts that are tested in this HW are copied/created in the ./example folder. The three types of dataflow analyses (liveness, availability, busy) were tested on the following :
birthday.brilcheck-primes.brilcond-args.brilcond.brilfact.brilin_class_example_1.brilin_class_example_2.brilin_class_example_3.brilis-decreasing.bril
To view the graph, set up a http server and use any of your favourite modern web browsers to open the .html file that just generated.
Example:
❯ cd HW3
❯ python -m http.server
Serving HTTP on 0.0.0.0 port 8000 (http://0.0.0.0:8000/) ...
# Goto http://<server-ip>:8000/output/in_class_example_1.bril/liveness/in_class_example_1.htmlLiveness Analysis
Liveness analysis was correctly computed in all test cases. The variables that were “live” at each point in the program were accurately tracked. The results were particularly effective in identifying opportunities for Trivial DCE. For instance, variables that were defined but never live in subsequent instructions were correctly flagged, highlighting code that could be safely eliminated.
Availability Analysis
Availability analysis was applied successfully, and all expressions available at the entry and exit of each basic block were correctly computed. This analysis is critical for Local Value Numbering (LVN), where equivalent expressions are consolidated. In benchmarks such as in_class_example_3.bril, the implementation showed how redundant computations could be eliminated by detecting available expressions early.
Busy Expressions Analysis
Busy expressions analysis worked as expected, identifying expressions that were critical to compute before the next use. This was particularly useful in loops, where understanding which expressions are “busy” helps optimize the repeated evaluation of the same values.
Comparison and Insights
For all test cases, I carefully compared the output CFG and dataflow graph to the expected results. No differences were found in any of the test cases, confirming that the implementation is consistent with the theoretical expectations for dataflow analysis.
The visual representation of the analysis results (generated using vis.js and networkx) provided an intuitive way to verify the correctness of the IN, OUT, GEN, KILL, and EXPR sets for each basic block. This helped to easily identify points of optimization and confirmed that the framework was operating as intended.
Raw test log
Check the following pages:
Typical Examples:
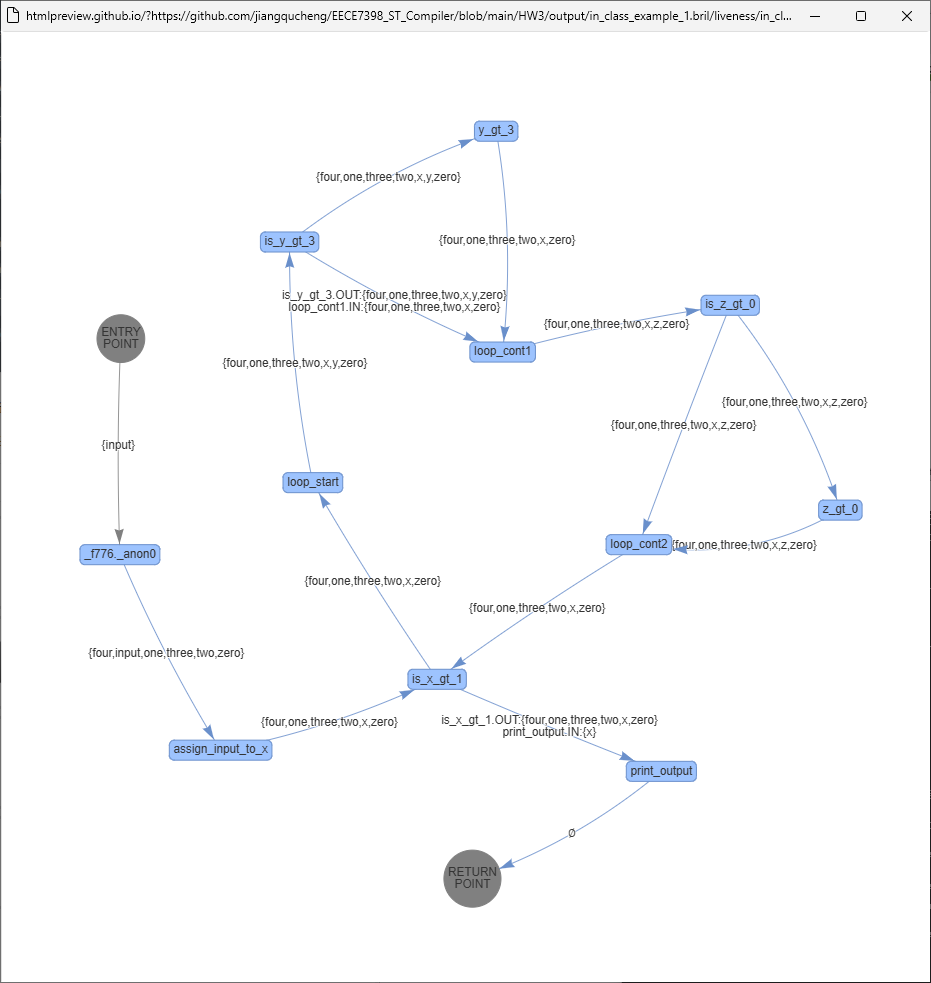
in_class_example_1.bril/liveness
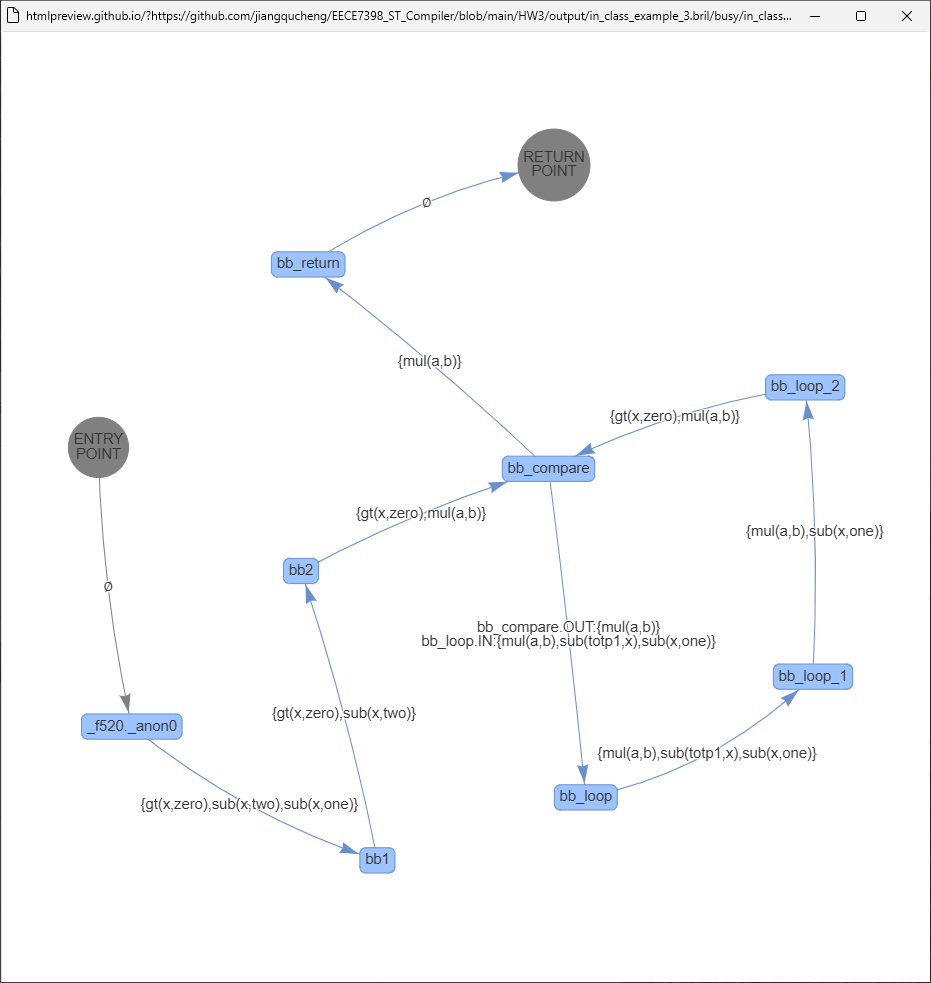
in_class_example_3.bril/busy
Conclusion
The dataflow analysis framework for Bril successfully implements liveness, availability, and busy expressions analyses, all of which are foundational for key compiler optimizations. Trivial Dead Code Elimination (DCE) and Local Value Numbering (LVN) will extremely benefit from these analyses by eliminating redundant computations and identifying unused variables.
The testing of the framework on various Bril programs—ranging from simple in-class examples to more complex benchmark scripts—demonstrates that the analyses work correctly and efficiently. The interactive visualizations of the control flow graph (CFG) and associated dataflow sets provide valuable insights, making it easier to verify correctness and identify optimization opportunities.
This project establishes a strong foundation for performing local optimizations on intermediate representations like Bril. Future work could extend the framework to handle interprocedural analyses, multi-block optimizations, or more advanced global dataflow analyses. By further refining these optimizations, we can significantly enhance the efficiency of compiled programs.