programming model
both vendors use the CUDA programming model. AMD supports a variation of the CUDA language
machines have multiple SIMD processors, each SIMD can be running a different instruction but each lane of a SIMD runs the same instruction
a lane of a SIMD is called a thread
the programming model is SIMT (single instruction multiple threads)
User writes a scalar program, compiler maps that program to a lane of a SIMD, many instances of the program run at once, hardware combines copies of the scalar program into warps, hardware schedules warps into the SIMD engines
programs are called kernels
Heterogeneous programming
the cpu is called the host
the gpu is called the device
cpu launches grids and kernels to gpu
Computations launched on the device execute asynchronously with respect to the host, and it is the user’s responsibility to synchronize
Hardware
NVIDIA
![]()
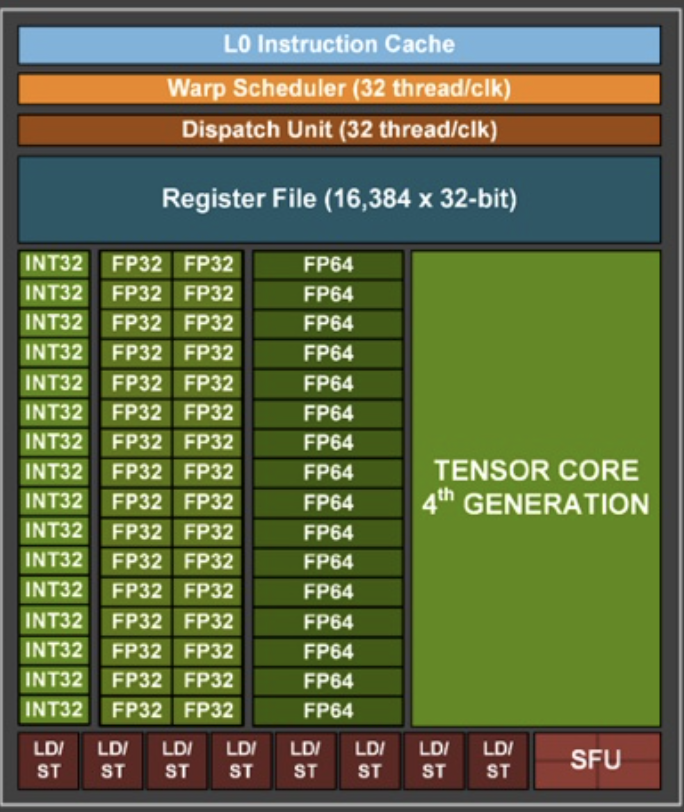
nv image level 0
Each box here is hardware, an int32/fp32/fp64 can perform one operation, so here we have 32 fp32 units which can do 32 float operations in parallel as well as 16 int32 and 16 fp64 units , there are also 8 units can do loads or stores and a final special function unit that can do transcendental operations like sin/cos
under some conditions two instructions (a float and an int) from the same warp can execute at the same time
I’m not going to talk much about the tensor cores
all these units execute the same instruction (SIMT) Simple instruction multiple thread (not the same as SIMD but related )
one instruction does vector work
add 32 float32 values (all coming from registers) and store the result in 32 other registers
Notice no branch prediction, no out of order execution
great at switching a warp holds the instruction, it knows which registers it owns (continuous set, so it just needs a start and length) switching to a different warp, means changing these two numbers and the pc (this is done by the dispatch unt )
When we do a load, we need to wait for the result. CPU might do some kind of out of order execution, a gpu switches to another warp
finally we need to pick the warp to switch to, this is done by the warp scheduler (half of the hardware scheduler)
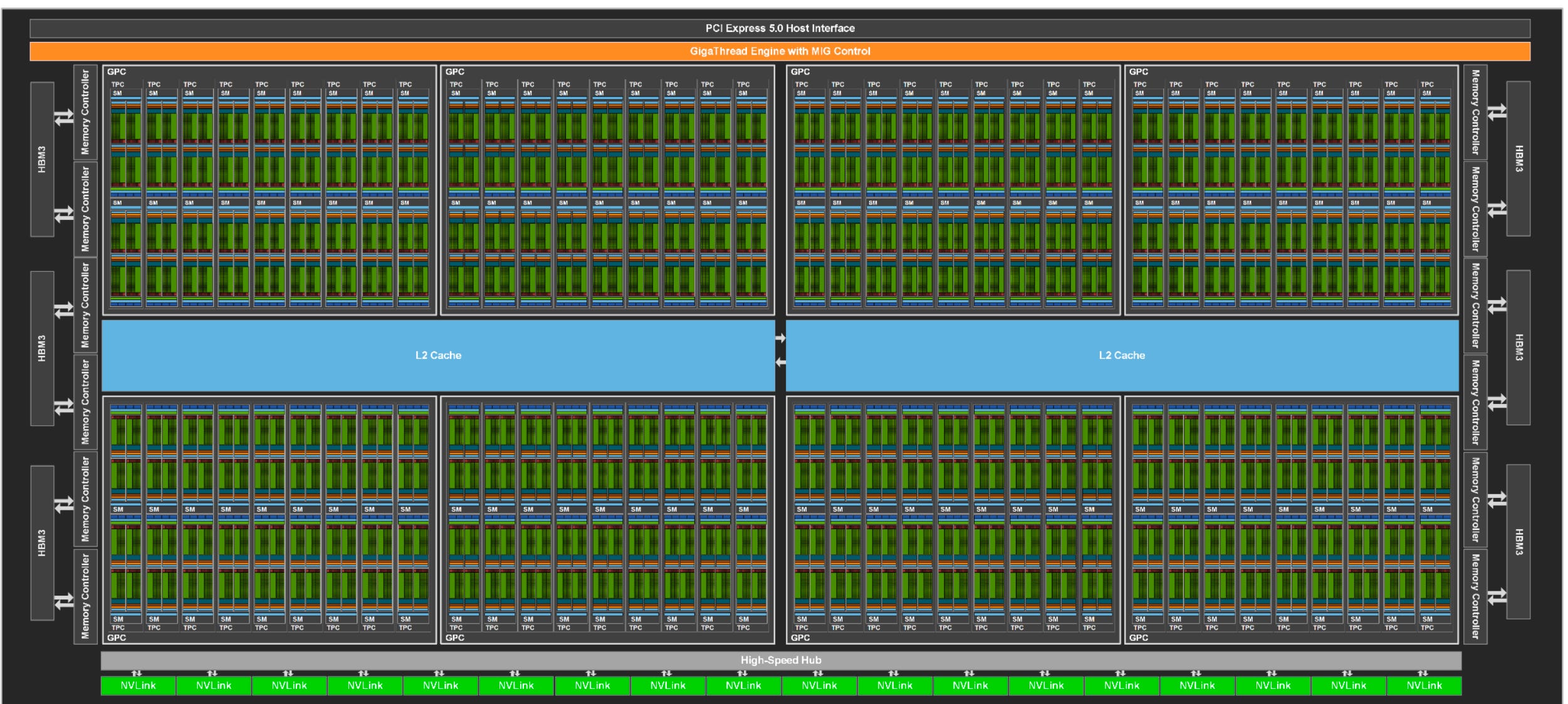
streaming multiprocessors (SM)
nvidia packs 4 execution engines into a SM (streaming multi-processor) ands an L1 instruction cache, a special memory accelerator for tensors and 256kb l1 data cache/ shared memory block
![]()
pack sm’s together
![]()
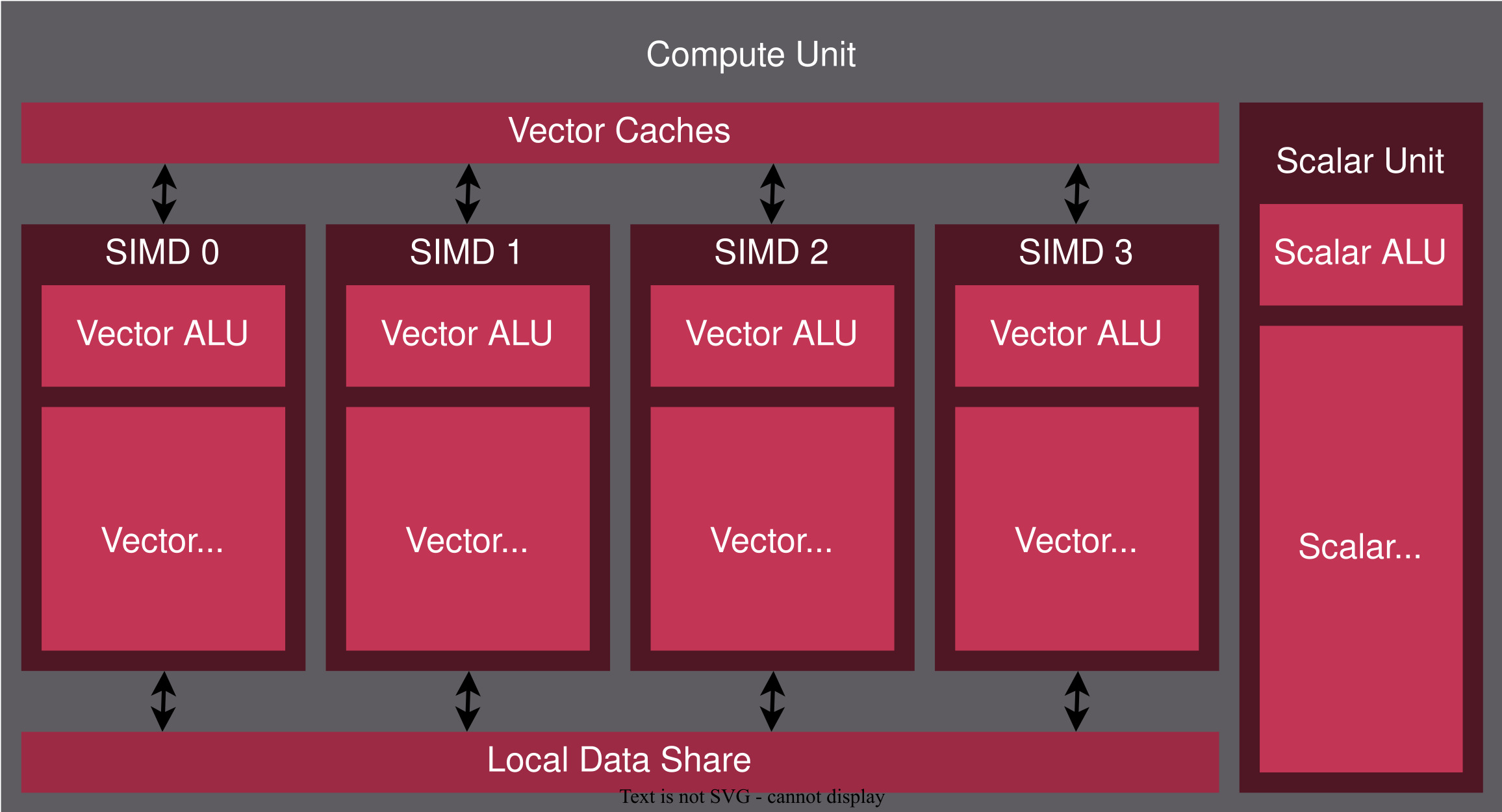
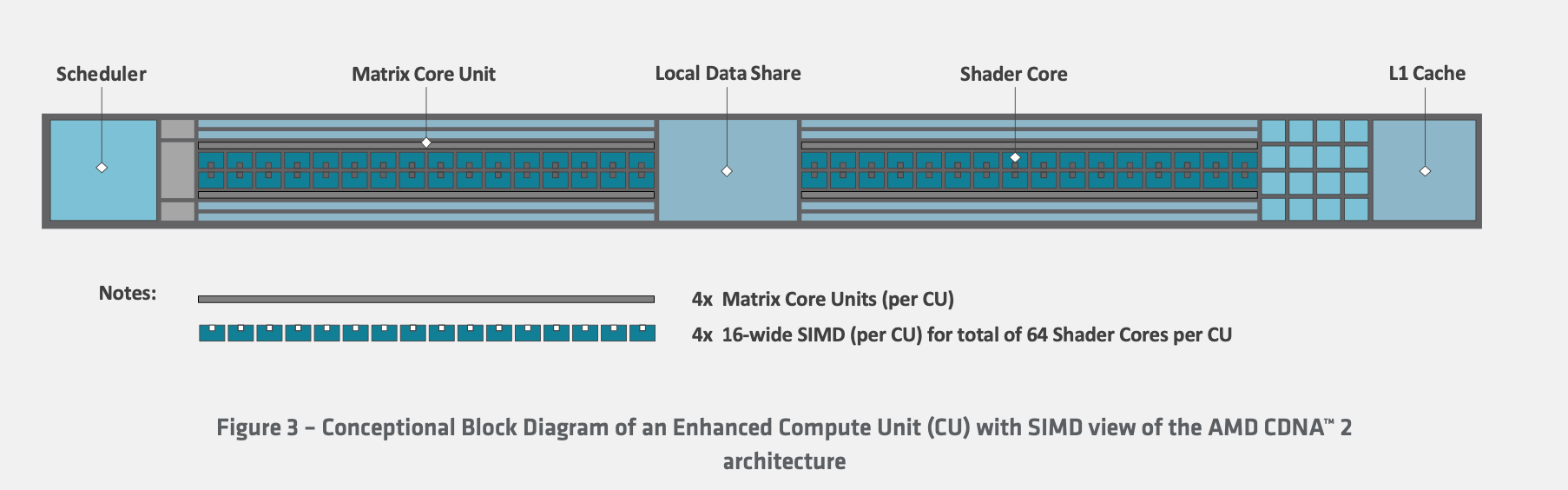
amd CDNA
![]()
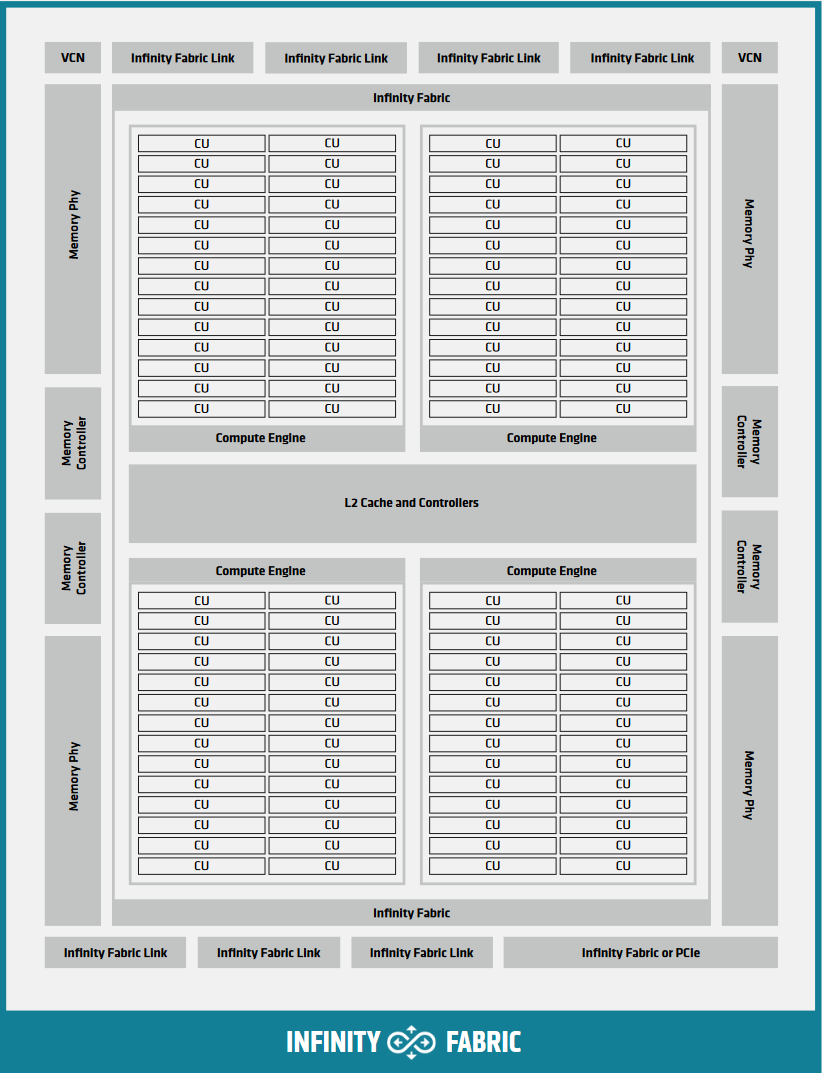
packing sms
![]()
number of warps in flight
since an entire block has to fit on one compute unit/sm, the resources used in the block limit the number of warps on a sm,
if a warp needs 100 registers and there are 256 vector registers on the compute unit, then two warps can run at once, compiler controls number of registers
thread coarsening
Suppose we are computing a matrix multiply
we could say each thread writes one result so a 32 x 32 matrix would need 32 * 32 threads each thread reads one column and one row of the input,
we have a lot of reuse (redundant loads of data )
we could say each thread writes 4 results, so we need 1/4 of the threads each thread reads a raw and 4 columns
doing this by hand
for (atomid=0; atomid<numatoms; atomid++) {
float dy = coory - atominfo[atomid].y;
float dysqpdzsq = (dy * dy) + atominfo[atomid].z;
float dx1 = coorx1 - atominfo[atomid].x;
float dx2 = coorx2 - atominfo[atomid].x;
float dx3 = coorx3 - atominfo[atomid].x;
float dx4 = coorx4 - atominfo[atomid].x;
energyvalx1 += atominfo[atomid].w * (1.0f / sqrtf(dx1*dx1 + dysqpdzsq));
energyvalx2 += atominfo[atomid].w * (1.0f / sqrtf(dx2*dx2 + dysqpdzsq));
energyvalx3 += atominfo[atomid].w * (1.0f / sqrtf(dx3*dx3 + dysqpdzsq));
energyvalx4 += atominfo[atomid].w * (1.0f / sqrtf(dx4*dx4 + dysqpdzsq)); } …